
Wie man Low Code Anwendungen mit einem in Deutschland betriebenen Backend integrieren kann.
Wenn man Technologien wie AWS, APIs oder Low Code nutzt, werden Daten in der Cloud gespeichert. Was aber tun, wenn die Daten möglichst auf einem heimischen Server bleiben sollen. Im Folgenden möchte ich kurz erklären, wie man beides haben kann - die Nutzung moderne Technologien sowie die Sicherheit, dass Daten auf einem deutschen Server gespeichert werden.
Zunächst möchte ich einige grundlegende Technologien und Anwendungsmuster erklären, die wir später zum Verständnis brauchen. Dabei handelt es sich sowohl um Aspekte der Softwarearchitektur als auch Patterns (Muster), welche erklären, wie man Technologien einsetzen kann.
Eine (Web-)Anwendung lässt sich grundsätzlich in drei Schichten aufteilen. Neuere Ansätze wie Serverless Computing lassen die Grenzen zwischen diesen Schichten allmählich verschwimmen. Nichtsdestotrotz lohnt sich die Betrachtung dieser Schichten zur Einordnung die Beispiele weiter unten. Hierbei handelt es sich um die Anzeige in der obersten Schicht, die Geschäftslogik in der mittleren Schicht und der Persistenz in der untersten Schicht. Die Abbildung verdeutlicht die drei Schichten.
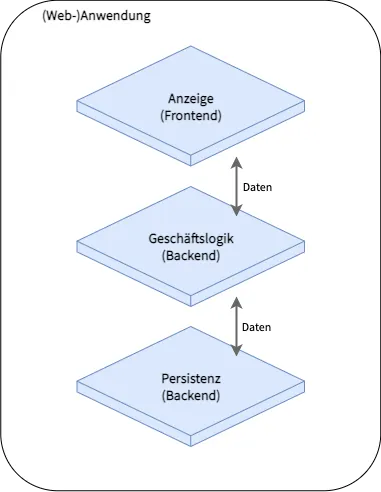
Architektur einer Anwendung mit drei Schichten
In dieser Schicht finden sich alle Elemente, mit denen ein User agiert. Im Umfeld von Webanwendungen sind das Dinge wie Buttons, Listen, Textfelder, Links oder einfache Texte. Synonyme Begriffe für diese Schicht sind User Interface (UI) oder Frontend.
In der mittleren Schicht finden sich die wahrgenommenen Funktionen einer Software. Das können zum Beispiel das Validieren und Verändern von Eingaben des Users, das Abarbeiten von Workflows oder das Versenden von E-Mail sein. Hinzu kommen in dieser Schicht oft die Authentifizierung und die Autorisierung - also das Identifizieren eines Users durch einen Login und das Ausstatten dieses Users mit Rechten zum Abruf bestimmter Daten.
Die unterste Schicht ist für das Speichern der Daten zuständig. Das wird in den allermeisten Fällen von Datenbanken erledigt. Möchte ein User Daten speichern oder abfragen, wird diese Operation von der mittleren Schicht validiert und autorisiert.
Wenn wir uns also mit der Frage beschäftigen wollen, wie man Daten auf einem deutschen Server speichern kann, dann schauen wir vor allem auf die Persistenz-Schicht bzw. auf die Datenbank. Natürlich werden die Daten einer Anwendung auch innerhalb der anderen beiden Schichten genutzt. Daher wollen wir uns zunächst kurz anschauen, wie Daten zwischen den Schichten transferiert werden.
Um den Fluss der Daten zwischen diesen drei Schichten zu erklären, können wir ein einfaches Beispiel zur Hilfe nehmen. Ein User eines Onlineshops schaut sich seine letzten Bestellungen an. Der User klickt in seinem Browser auf einen Button “Bestellungen anzeigen” (oberste Schicht - UI). Der Request wird von der mittleren Schicht validiert, der User wird identifiziert und die zum User gehörenden Bestellungen werden von der Datenbank abgerufen. Die Datenbank (unterste Schicht - Persistenz) stellt die Bestelldaten zur Verfügung und die Geschäftslogik (mittlere Schicht) schickt die Daten zurück zum Browser des Users.
An diesem Ablauf lassen sich zwei weitere Begriffe sehr gut erklären: Encryption at rest und encryption at transfer. Diese beiden Konzepte sind von Belang, da es uns um die Sicherheit der Daten geht. Das ist wichtig, da sich die Daten in Webanwendungen nicht nur auf unserem eigenen Server befinden, sondern auch über das Internet an den Browser des Users übertragen werden.
Sobald die Daten den Server verlassen, sollten sie verschlüsselt übertragen werden. Die Verschlüsselung während der Übertragung wird als encryption at transfer bezeichnet. In dem oben beschriebenen Beispiel befinden sich die Daten in Übertragung, sobald die Geschäftslogik sie an den Browser ausliefert. Sofern die Übertragung verschlüsselt ist, sind die Daten weitestgehend vor dem Auslesen oder Verändern durch Dritte geschützt.
Der Begriff transfer at rest beschreibt die Verschlüsselung der Daten im Zustand der Speicherung. Das erfolgt meist dadurch, dass das Speichermedium des Servers, auf dem die Datenbank betrieben wird, verschlüsselt ist.
Die Daten, die in Webanwendungen verarbeitet werden, verlassen also regelmäßig den eigenen Server. Daher ist es wichtig, für die Verschlüsselung während der Übertragung (encryption in transfer) zu sorgen. Damit sind sie während der Übertragung geschützt und unsere Bemühungen sie auf einem deutschen Server zu speichern nicht durch die Übertragung zunichtegemacht.
Beim Aufbau von Anwendungen in Cloud-Architekturen ist es an der Tagesordnung, dass Daten zwischen zwei verschiedenen Anwendungen ausgetauscht werden. Dabei kann zum Beispiel die Funktionalität einer Anwendung durch eine zweite Anwendung erweitert werden. Ebenso oft wird eine Anwendung als zwei separate Komponenten betrieben. So kann zum Beispiel das Frontend einer Webanwendung eine eigene Anwendung darstellen, welche über das Internet mit einem Backend (der Begriff vermengt Geschäftslogik und Persistenz) kommuniziert.
In beiden Fällen werden Daten über das Internet ausgetauscht. Für diesen Austausch wird oft eine API (Application Programming Interface) als Schnittstelle zwischen beiden Komponenten verwendet. Die API kann mithilfe eines Secrets gegen den Zugriff Dritter abgesichert werden. Somit bleiben die unteren Schichten der Webanwendung gegen den unbefugten Zugriff geschützt. Zusätzlich werden die Daten während der Übertragung verschlüsselt (encryption at transfer). Diese beiden Mechanismen lassen und verteilten Anwendungen absichern.
Nachdem wir uns nun mit den grundlegenden Aspekten der Architektur von Webanwendungen beschäftigt haben, wollen wir uns eine konkrete mögliche Implementierung anschauen. Im Folgenden verwende ich den Begriff Frontend für die oberste Schicht und den Begriff Backend für die Geschäftslogik sowie die Persistenz.
Mit Low Code Tools (zur Erklärung, was Low Code ist: Low Code FAQ) lassen sich sehr effizient und schnell Webanwendungen entwickeln. Besonders die visuellen Editoren sind geeignet, um Frontends zu entwickeln und Interaktionen des Users mit der Anwendung zu gestalten. Viele der Low Code Tools umfassen alle drei vorgestellten Schichten. Das heißt, dass sie nicht nur UIs und Logik abbilden, sondern auch Daten abspeichern. Wenn wir nun aber die Speicherung der Daten selbst in die Hand nehmen wollen, müssen wir diese Schicht bzw. das Backend ersetzen.
Viele Low Code Tools lassen die Integration von APIs zu. Wir können als über APIs Daten übertragen und so unser Frontend vom Backend entkoppeln. Es bleibt dann auf der einen Seite ein Low Code-basiertes Frontend und auf der anderen Seite eine selbst betriebenes Backend. Die Kommunikation dazwischen basiert auf einer API. Eine Lösung für ein selbst betriebenes Backend ist die Open-Source-Software supabase, welches im weiter unten noch genauer beschrieben wird.
Das Low Code Frontend übernimmt dabei zum Beispiel die folgenden Aufgaben:
Die restlichen Aufgaben des Backends kann supabase übernehmen:
Die oben genannte Open-Source-Software kann eingesetzt werden, um ein Backend zu betreiben. supabase ist so konzipiert, dass es in der Cloud betrieben werden kann. Man kann mit supabase also ein Backend selbst betreiben und dabei Cloud Provider wie AWS oder die Google Cloud Plattform benutzen. Bei beiden Providern kann man strikt auf den Betrieb der Server in Deutschland achten. So kann supabase gleichzeitig in der Cloud und auf deutschen Servern betreiben werden. supabase speichert die Daten in einer PostgreSQL-Datenbank. Da diese selbst konfiguriert werden kann, ist hier sichergestellt, dass die Daten in Deutschland gespeichert werden. Datenbanken, die bei einem Cloud-Provider betrieben werden, können, ebenso wie Server, strikt auf einen bestimmten Standort beschränkt werden. Damit eignet sich supabase als ein Cloud-basiertes Backend, welches vollständig in Deutschland betrieben werden kann. Die Abbildung unten zeigt, wie supabase innerhalb der drei Schichten einzuordnen ist.
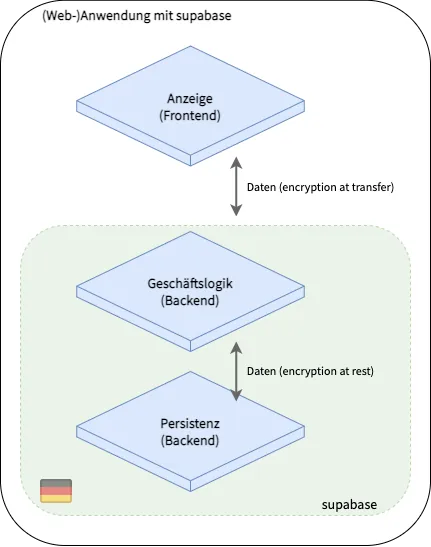
Low Code Webanwendung mit supabase
Das beschriebene Beispiel zeigt, dass wir keineswegs wählen müssen zwischen dem Betrieb auf einem Server in Deutschland und der Nutzung von modernen Technologien wie Cloud oder Low Code. APIs als Bindeglied ermöglichen uns ein Low Code-Frontend mit einem in Deutschland betriebenen supabase-Backend zu verbinden.

Erzähle uns in einem kostenlosen Erstgespräch mehr über dein individuelles Projekt. Wir helfen dir bei den nächsten Schritten und teilen unser Wissen.
Nachricht schreiben